
Новая технология Hyper-Threading от Intel уже успела наделать много шума среди разработчиков программного обеспечения (см. статью Владимира СИРОТЫ «Бурный поток вычислений», МК №48 (219)). Еще бы, ведь создание продуктов для работы в системе с несколькими процессорами требует кардинально нового подхода, я бы даже сказал, нового типа мышления. Однако необходимость отхода от ортодоксальных догм программирования в данном случае более чем оправдана, в первую очередь увеличением производительности. Данная статья призвана познакомить вас с новыми концепциями создания программ, которые, вероятно, скоро заменят традиционные решения.
Итак, для тех, кто еще не знает, Hyper-Threading Technology — уникальная новинка от Intel Corporation. Эта технология открывает огромные возможности для приложений, использующих параллельно выполняемые процессы. В отличие от уже привычной многопотоковости, Hyper-Threading использует не разделение процессорного времени, а разделение самого процессора. Все просто: допустим, у нас есть один процессор. Одна короткая команда — и их уже два, при этом каждый из «дочерних» процессоров имеет свои собственные задачи, которые и решает абсолютно независимо от своего «собрата по транзисторам». Конечно же, на физическом уровне никакого деления не происходит, процессоры — не грибы, не почкуются на материнке после дождичка :-). Зато на логическом уровне у компьютера появляется новый процессор, под который выделяются регистры и ресурсы. Главным же является то, что «дети» перенимают все свойства «родителя», а ведь это не только список допустимых к выполнению команд, но и возможность повторного деления. Не менее важен также тот факт, что деление вызывается командой программы, а это значит, что теперь программа сама может определять, сколько процессоров ей нужно для решения поставленных задач.
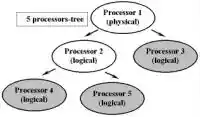
Дерево процессоров
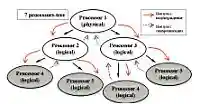
По генеральной задумке разработчиков, программа будет «дробить» процессоры до тех пор, пока не достигнет нужного ей количества. При этом формируется так называемое processors-tree (дерево процессоров). Примеры такого дерева показаны на Рис. 1 и Рис. 2. При этом активными (active) являются только процессоры самого последнего уровня (те процессоры, которые не имеют собственных «потомков»). Сказать, что такие логические процессоры работают полностью автономно друг от друга, все-таки нельзя. На самом деле они должны постоянно синхронизироваться друг с другом. Импульс синхронизации поступает от каждого активного процессора к корню дерева (корнем дерева является самый первый процессор — физический). После того как все импульсы успешно достигли точки назначения, «корень» посылает импульс-подтверждение каждому из активных процессоров. Схема прохождения сигнала изображена на Рис. 2. Разумеется, сигнал от конкретного активного процессора будет идти тем дольше, чем дальше этот процессор удален в дереве от своего физического «прадедушки» (благо, хоть сигнал может поступать ото всех процессоров одновременно). На первый взгляд, такая непривычная трата ресурсов и времени не вяжется с обещанным увеличением производительности, но в дальнейшем вы убедитесь, что синхронизация почти не замедляет работы программы в целом.
Основные принципы
Чтобы уменьшить тормозящий эффект обязательной процедуры синхронизации, разработчики Intel советуют программистам проектировать программы так, чтобы те создавали как можно более сбалансированное дерево процессоров, то есть расстояние от корня до всех активных процессоров должно быть одинаковым. Иначе некоторые процессоры будут простаивать, синхронизируясь с более удаленными от «прародителя» собратьями. С этой точки зрения дерево на Рис. 2 является более удачным, чем дерево на Рис. 1. Также очень важно помнить о том, что никакой другой информацией процессоры не обмениваются, а значит, программа должна распределять между процессорами только независимые задачи (решение каждой отдельно взятой задачи не должно зависеть от решения задач, определенных под другие процессоры). Например, при создании трехмерной сцены нельзя поручать рендеринг двух рядом стоящих зеркал разным процессорам (не будет отображено многократное отражение зеркал друг в друге). Еще одним важным принципом работы Hyper Threading является то, что, поделившись, процессор-родитель передает управление своим «детям», а сам становится неактивным (not active). Обратно управление процессор получает только после того, как оба его потомка отрапортовали о завершении своей работы. Вышеперечисленные принципы и правила будут справедливыми по отношению к любой программе, работающей с Hyper Threading.
Пример программы
К сожалению, мне не удалось раздобыть модуль для Delphi (как, впрочем, и для других компиляторов Pascal), поддерживающий Hyper-Threading Technology (наверное, ждут официального выхода технологии). Совсем по-другому дела обстоят с C++. Ввиду наличия необходимой библиотеки (скачанной с ), мы напишем пример нашей мультипроцессорной программы на этом языке:
`#include "Hyper_Threading_Technology_service.h" // Модуль, обеспечивающий поддержку мультипроцессорной технологии — в нем описан базовый класс Processor #include void Base(Processor Current) { if (Current.level==10 ) // Если процессор имеет уровень 10 (удален от корня дерева на 9 процессоров) { cout<<"Processor done"<